8 min to read
LangChain in One Post
The open-source project that went from zero to 50,000 GitHub stars in three months — and why every LLM app still uses its ideas

On November 30, 2022, OpenAI released ChatGPT. The internet lost its mind. Within days, engineers everywhere were trying to figure out how to build applications on top of it.
Six weeks later, a developer named Harrison Chase pushed a project called LangChain to GitHub and posted it on Hacker News.
The premise was simple: calling an LLM once is easy. Building something useful almost always requires calling it multiple times, with different prompts, feeding the output of one call into the next, pulling in context from external sources, sometimes letting the model decide what to do next. LangChain gave you the building blocks to do all of that in a composable way — like LEGO bricks for LLM workflows.
Within three months it had 50,000 GitHub stars. Within six months it was raising a $10 million seed round. It had become, almost overnight, the default framework for building with language models.
That trajectory has never quite happened before in open source. But it makes sense when you understand what problem it solved.
The Problem: One LLM Call Is Never Enough
The first thing every developer does with a language model is write a messages.create() call and get a response. That works for demos.
Real applications are more complicated:
- A chatbot needs to remember what was said earlier in the conversation
- A research tool needs to pull in documents before answering a question
- An agent needs to look at the user’s request, decide which tool to use, use it, and then respond
- A multi-step workflow needs the output of step 1 before it can write the prompt for step 2
None of those things are hard individually. But wiring them all together, in a way that’s testable, debuggable, and reusable across projects? That’s where it got painful before LangChain.
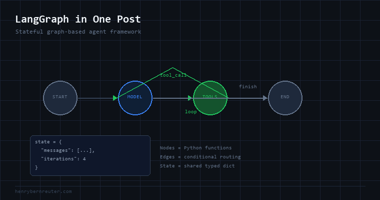
The Core Ideas
LangChain introduced four concepts that are now standard vocabulary in the AI engineering world.
Chains — a sequence of LLM calls where the output of one becomes the input of the next. You define the sequence once, then run it on any input.
Memory — a way to persist conversation history so the model knows what was said earlier. Without memory, every message is the first message. With it, the model can refer back to what the user told it five turns ago.
Retrievers and RAG — Retrieval-Augmented Generation. Before answering, search a knowledge base for relevant documents, inject them into the prompt. This is how you give a model access to information it was not trained on — your company’s docs, a user’s files, a live database.
Agents — instead of telling the model what to do, you give it a set of tools and let it decide which ones to use. The model reads a task, picks a tool (search the web, run code, query a database), runs it, reads the result, and decides what to do next.
These four patterns are in virtually every serious LLM application built today. LangChain did not invent all of them — but it named them, made them composable, and packaged them in a way that any developer could pick up.
Let’s Build Something
Here is a simple RAG pipeline — the most common real-world LangChain pattern. We have a set of documents. We want to ask questions about them and get answers grounded in the actual content.
pip install langchain langchain-anthropic langchain-community chromadb
from langchain_anthropic import ChatAnthropic
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
# Your documents
docs = [
"The quarterly revenue for Q1 2026 was $4.2M, up 23% year-over-year.",
"Customer churn rate in Q1 dropped to 2.1%, the lowest in company history.",
"The engineering team shipped 14 features in Q1, including the new API gateway.",
"Sales headcount grew from 12 to 18 in Q1. Pipeline coverage is currently 3.2x.",
]
# Split into chunks (here each doc is already a chunk, but for real docs you'd split)
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.create_documents(docs)
# Store in a vector database so we can search by meaning, not just keywords
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = Chroma.from_documents(chunks, embeddings)
# Build the QA chain
llm = ChatAnthropic(model="claude-haiku-4-5-20251001")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 2}),
)
# Ask it a question
result = qa_chain.invoke("How did churn and revenue trend in Q1?")
print(result["result"])
In Q1 2026, both key metrics moved in the right direction: revenue reached $4.2M,
up 23% year-over-year, while customer churn dropped to 2.1% — the lowest rate
in company history. Both improvements together suggest stronger product-market fit.
The model never saw those specific documents during training. It retrieved the relevant ones at query time, read them, and synthesized an answer. This is the pattern that makes LLMs useful for private, up-to-date knowledge.
A Simple Agent
Here is the agent pattern — the model decides what to do based on available tools:
from langchain_anthropic import ChatAnthropic
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_core.tools import tool
from langchain_core.prompts import ChatPromptTemplate
@tool
def get_weather(city: str) -> str:
"""Get the current weather for a city."""
# In a real app, this would call a weather API
return f"It is currently 72°F and sunny in {city}."
@tool
def get_population(city: str) -> str:
"""Get the population of a city."""
populations = {"Atlanta": "498,715", "New York": "8.3M", "Austin": "978,908"}
return f"{city} has a population of {populations.get(city, 'unknown')}."
llm = ChatAnthropic(model="claude-sonnet-4-6")
tools = [get_weather, get_population]
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
agent = create_tool_calling_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
result = executor.invoke({"input": "What's the weather and population of Atlanta?"})
print(result["output"])
The model decides to call both tools, reads both results, and writes a combined answer. You didn’t tell it to use both — it figured that out from the question.
Why This Still Matters
LangChain has had its critics. The early versions were over-engineered and hard to debug. The abstractions leaked. There were periods where the community questioned whether you needed the framework at all, or should just call the API directly.
Both things are true: LangChain got too complex early on, and the underlying patterns it named are essential.
The newer langchain-core and LCEL (LangChain Expression Language) are cleaner. But even if you never import LangChain again, you are still building chains, using memory, retrieving documents before prompting, and making agents. Those patterns are in every serious LLM application. LangChain just put names to them first.
In 2026, most production AI systems are some combination of: a retrieval layer, a memory layer, one or more LLM calls, and a tool execution layer. That architecture — the one LangChain described when GPT-3.5 was brand new — is now just how you build things.
The One Thing to Remember
LangChain gave developers a vocabulary for the patterns that appear in every LLM application — chains, memory, retrieval, agents — and made those patterns composable before anyone else had named them.
Harrison Chase shipped it six weeks after ChatGPT. The timing was perfect, the core ideas were right, and the community was hungry. Whether you use the framework or not, you are building in its shadow.
Next in this series: Hugging Face — how three French developers turned a teenage chatbot company into “the GitHub of machine learning,” and why their Transformers library is where virtually every modern AI model lives.